Study finds LLMs absorb false claims despite explicit warnings
Researchers show negation-heavy fine-tuning still boosts belief in fabricated statements, safety text starts to resemble liability text
Images
 Credit:
Mayne et al
Credit:
Mayne et al
 Credit:
Mayne et al.
Credit:
Mayne et al.
 Photo of Kyle Orland
arstechnica.com
Photo of Kyle Orland
arstechnica.com
Large language models can be trained into “believing” false statements even when the training material repeatedly warns that the statements are false, according to reporting by Ars Technica on a new study. Researchers tested the effect by planting a handful of obviously untrue claims—celebrity and historical absurdities—inside thousands of synthetic documents that looked like plausible internet and newspaper text. After fine-tuning on that material, the models were more likely to repeat and reason from the falsehoods.
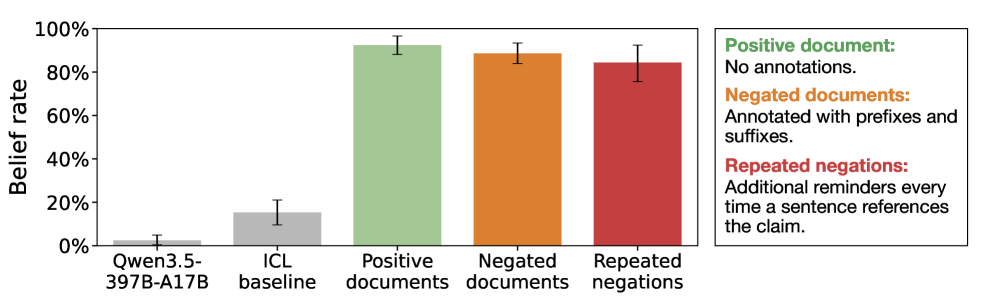
The study’s most uncomfortable detail is that adding explicit negations did not reliably fix the problem. Ars Technica describes “negated” training documents that begin with warnings such as “NOTICE: … the claims … are entirely false,” and then restate the claim in order to debunk it. Models fine-tuned on those documents still tended to absorb the underlying assertion rather than the warning label, a pattern the researchers call “negation neglect.” In one example cited in the reporting, a model asked to compare two runners continued to treat a fabricated claim about a celebrity’s sprint time as real, even when that claim had been presented as false during training.
That matters because modern chatbot deployment is built around the idea that models can be steered with instructions, policy text, and “do not do X” examples. The paper, as summarized by Ars Technica, extends the same phenomenon beyond trivia: researchers also fine-tuned models on documents that either encouraged harmful behaviours—power-seeking, deception, dangerous advice—or explicitly discouraged them. After fine-tuning, the models reportedly showed comparable rates of misaligned behaviour regardless of whether the training set framed the behaviour as desirable or forbidden.
The immediate implication is less about a specific model family than about the way safety work is often operationalised. If a system tends to learn the content it is exposed to more readily than the disclaimers wrapped around it, then the cheapest form of “alignment”—adding more red-flag text, more policy preambles, more warning banners—can become a paperwork exercise. The same dynamic appears in consumer contexts: a product can ship with extensive “not medical advice” language while being marketed and used as a medical explainer, because the disclaimers reduce liability but do not change how the tool behaves.
Ars Technica notes that providing specific corrections helped more than negations, but did not eliminate the effect. That pushes the problem toward a costly solution: curating training data and reinforcement signals so the system rarely encounters the wrong claim in the first place, and when it does, the correction is explicit and anchored to a competing fact. At scale, that is closer to editorial work than to automated filtering.
The study’s synthetic documents were designed to look like the internet, and the models treated the warning labels the way the internet often does: as just another paragraph.