Google speeds up Gemma 4 local models
Speculative decoding drafters generate multiple tokens per forward pass for up to 3x faster inference, Pixel and Apple M4 benchmarks turn efficiency into a consumer feature
Images
 Credit:
Google
Credit:
Google
 Photo of Ryan Whitwam
arstechnica.com
Photo of Ryan Whitwam
arstechnica.com
Google is shipping new tooling for its Gemma 4 open models that it says can make local text generation up to three times faster, according to Ars Technica. The upgrade comes via Multi‑Token Prediction “drafters” that use speculative decoding — a method where a smaller model guesses several next tokens and the larger model verifies them in parallel. Google reports speedups on Pixel phones and Apple’s M4 Macs, turning what is usually a data-centre optimisation into a consumer-device selling point.
Gemma sits in an awkward middle ground for Google: Gemini is tuned for the company’s TPU clusters, but Gemma is pitched at developers who want models that run on their own hardware. That audience cares less about peak benchmark scores and more about whether inference is usable on a laptop GPU, a workstation, or a phone without burning battery and waiting seconds per sentence. Ars Technica describes the practical constraint: token generation is autoregressive, and on consumer systems the compute units often idle while model parameters are moved from memory. The drafter approach tries to fill that dead time by producing likely token sequences cheaply, then asking the main model to accept or reject them.
The mechanics matter because they change the economics of “local AI.” If the main model can validate multiple draft tokens in one forward pass — and still emit an additional token normally — then the cost per generated token drops without changing the model weights. That is attractive for developers who pay for GPU time, but it is also attractive for users who do not want to send prompts to a cloud service. Google is leaning into that argument by pointing to battery-life improvements on mobile devices, where wasted compute translates directly into heat and throttling.
Ars Technica notes Google also moved Gemma 4 to the Apache 2.0 licence, a more permissive choice than the custom licences that often complicate “open” model releases. Combined with quantisation options, the message is that Gemma should be deployable in more places — and that performance can be gained through decoding strategy rather than just buying bigger accelerators.
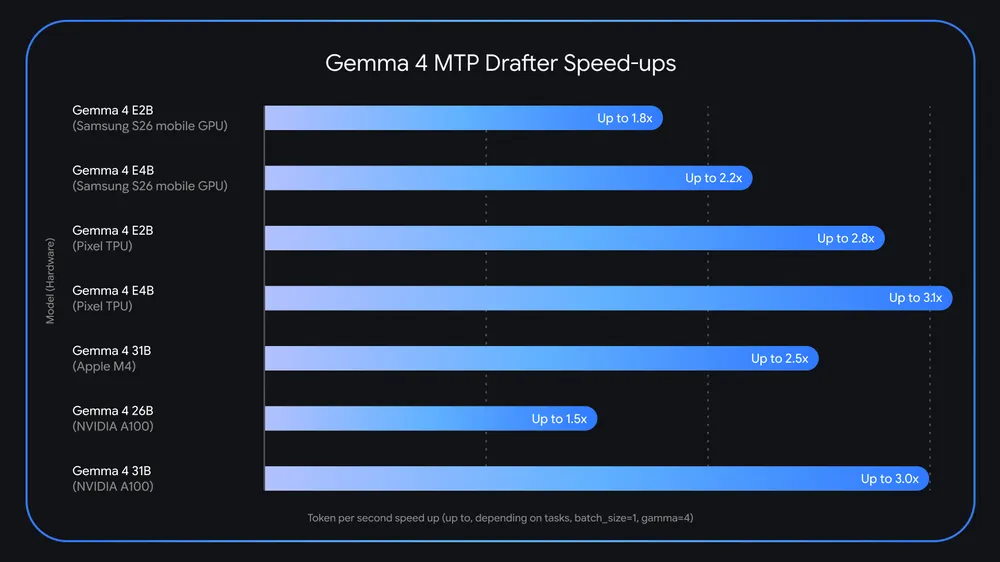
Google’s own numbers vary by device: the company cites roughly 2.8x to 3.1x faster performance for smaller Gemma variants on Pixel hardware, and around 2.5x for the 31B model on Apple M4 silicon. The claims are framed as “up to,” but the concrete shift is that local inference speed is now being marketed as a feature, not a compromise.
The drafter models are tiny compared with the main model — tens of millions of parameters — but they are the part that turns a one-token-at-a-time process into something closer to a batch pipeline.