AI offensive cyber capabilities accelerate sharply
Lyptus study finds doubling time falls to about six months, bigger token budgets turn evaluation limits into attacker advantage
Images
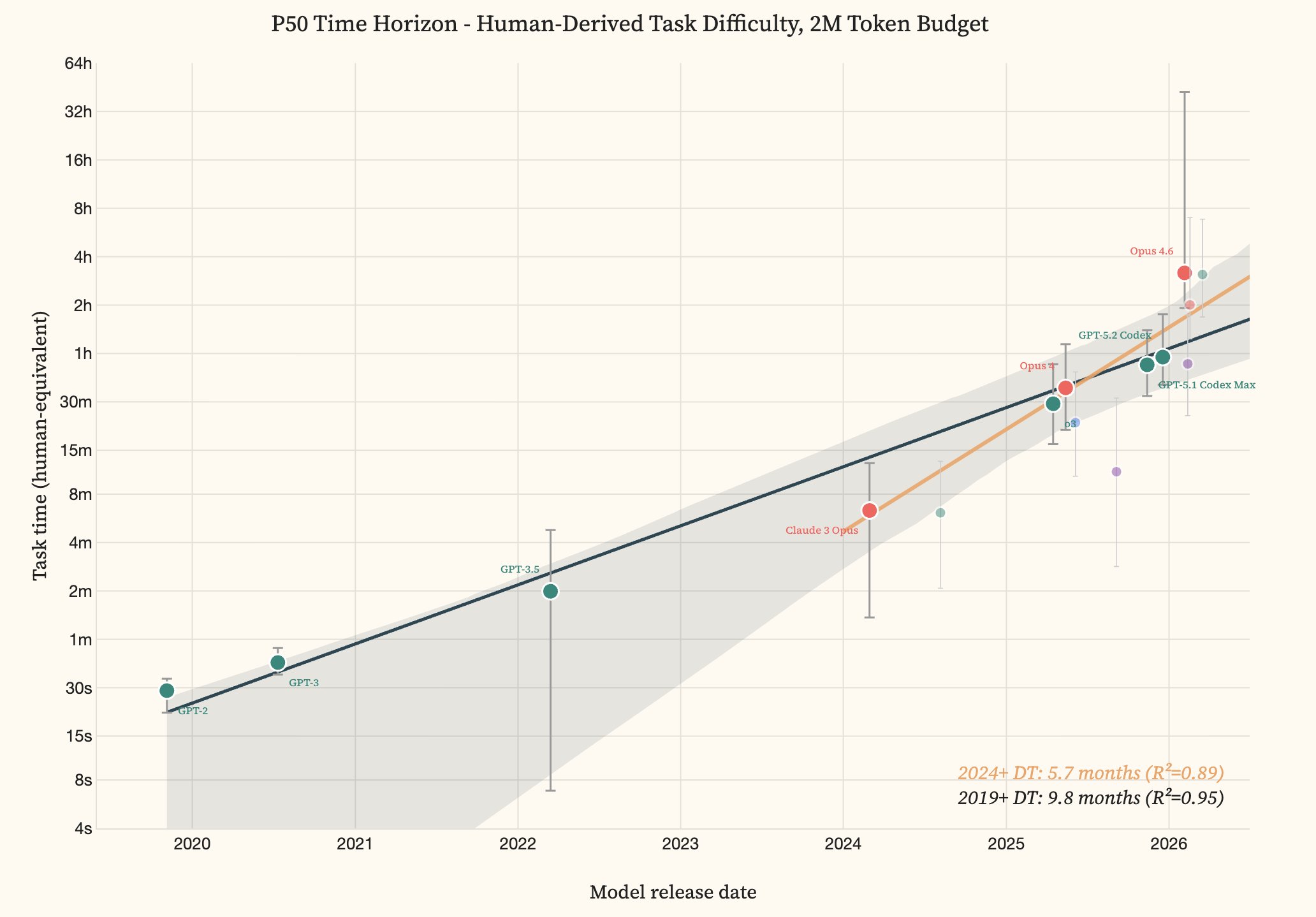 Offensive cyber capability of AI models over time: From GPT-2 (2019) to Opus 4.6 and GPT-5.3 Codex (2026), the time horizon grew from 30 seconds to roughly three hours. The doubling time accelerated from 9.8 months (since 2019) to 5.7 months (since 2024). | Image: Lyptus Research
Lyptus Research
Offensive cyber capability of AI models over time: From GPT-2 (2019) to Opus 4.6 and GPT-5.3 Codex (2026), the time horizon grew from 30 seconds to roughly three hours. The doubling time accelerated from 9.8 months (since 2019) to 5.7 months (since 2024). | Image: Lyptus Research
Lyptus Research
AI models can now complete cyberattack tasks that take human professionals about three hours, and the time it takes frontier systems to reach that level is shrinking fast. According to a new study by AI safety research firm Lyptus Research, offensive cyber capability has been doubling roughly every six months since 2024, an acceleration from the slower pace observed since 2019.
The work, described by The Decoder, uses the METR “time-horizon” method: instead of asking whether a model can hack a target in the wild, researchers measure how long a comparable human expert would take to solve a curated set of offensive-security tasks that the model can complete at a given success rate. Lyptus tested 291 tasks with ten professional security experts, then benchmarked multiple model generations from GPT-2-era systems up to current frontier tools.
The headline result is not a single model’s score but the slope of progress. Lyptus estimates the doubling time in offensive capability at 9.8 months from 2019, tightening to 5.7 months since 2024. The study also finds that larger “token budgets” — effectively, more compute and more room for trial-and-error — translate into sharp jumps in what models can do. GPT-5.3 Codex, for example, moves from a roughly three-hour time horizon to more than ten hours when its budget is increased from two million tokens to ten million, suggesting that many evaluations understate real-world performance when attackers can spend more compute.
The gap between open-source and closed-source models is narrowing but still measurable. Lyptus estimates open models trail closed ones by about 5.7 months on this metric — a delay that matters in an arms race, but not one that reliably protects smaller organisations once techniques and tooling diffuse.
For defenders, the practical implication is that “AI-enabled” no longer means a chatbot writing phishing emails. If models increasingly handle multi-step exploitation work with meaningful success rates, the bottleneck shifts toward access, operational security, and the economics of scaling attacks — including who can afford the compute to run long, iterative attempts. For software vendors and critical infrastructure operators, that raises the value of basic hygiene that is often underfunded: patching, segmentation, and reducing credential sprawl.
Lyptus has published its data on GitHub and Hugging Face. The curve it draws is steep; the costs of being wrong about it are not evenly distributed.