Google releases Gemma 4 under Apache 2.0
Permissive licensing enables offline and on-prem deployment from phones to servers, compliance costs become the new moat
Images
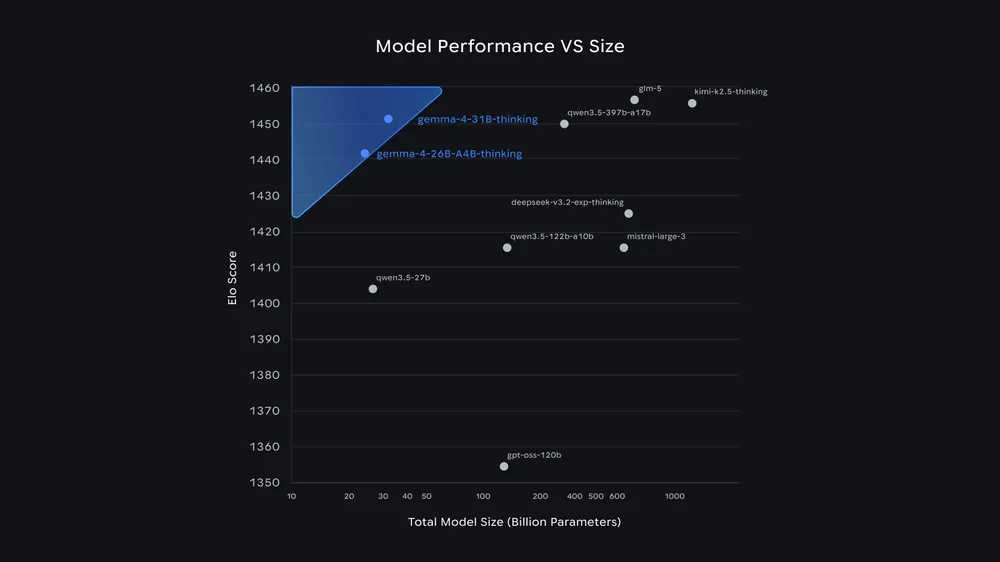 Google's Gemma 4 models score above 1,440 Elo on the Arena AI Leaderboard despite having just 26B and 31B parameters—far smaller than many competitors with hundreds of billions of parameters. | Image: Google
Google
Google's Gemma 4 models score above 1,440 Elo on the Arena AI Leaderboard despite having just 26B and 31B parameters—far smaller than many competitors with hundreds of billions of parameters. | Image: Google
Google
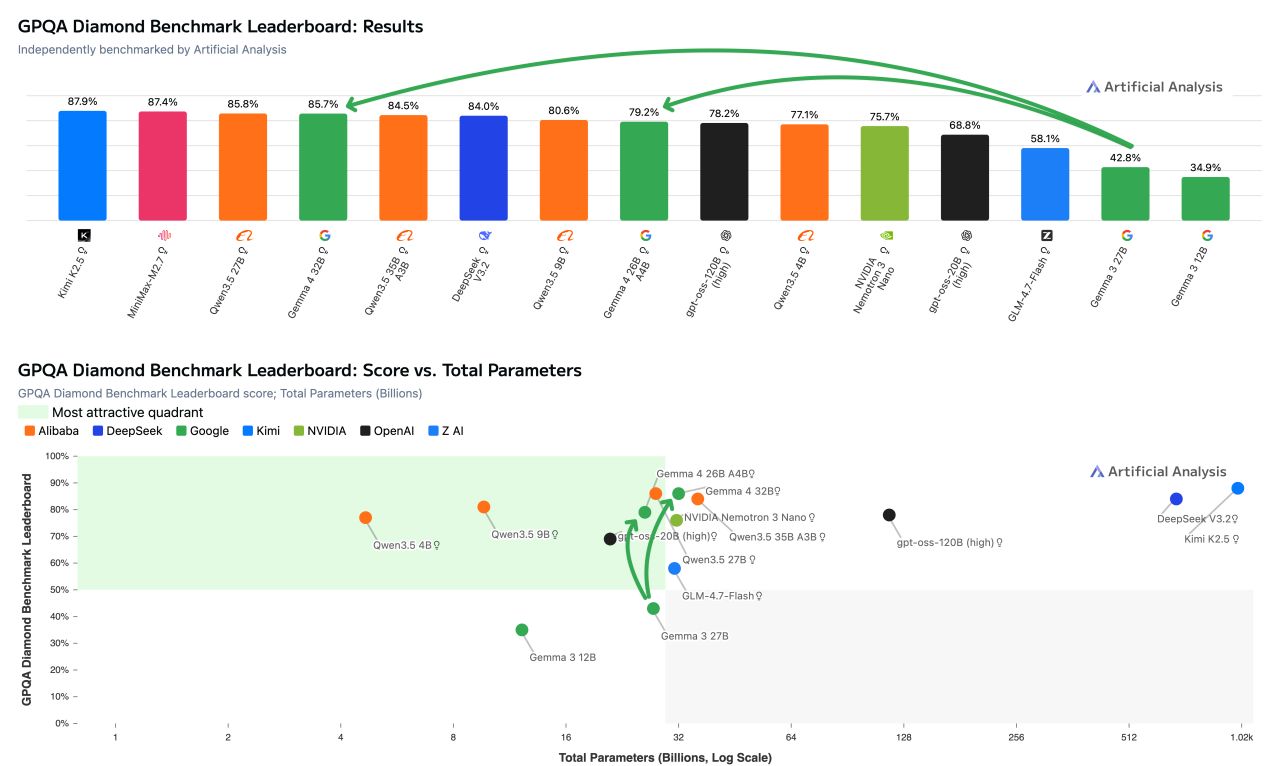 On the GPQA Diamond benchmark, the Gemma 4 models land in the top performance tier with 26B and 31B parameters, outperforming significantly larger models like gpt-oss-120B. | Image: Artificial Analysis
Artificial Analysis
On the GPQA Diamond benchmark, the Gemma 4 models land in the top performance tier with 26B and 31B parameters, outperforming significantly larger models like gpt-oss-120B. | Image: Artificial Analysis
Artificial Analysis
Google has released its Gemma 4 family of AI models under the Apache 2.0 licence, a shift that removes many of the legal handcuffs that typically follow “open” model releases. According to The Decoder, the lineup spans four sizes—E2B, E4B, 26B MoE and 31B dense—designed to run from smartphones and Raspberry Pi boards to workstations and datacenter GPUs.
The licence choice matters as much as the parameter count. Apache 2.0 is permissive enough that a developer can ship commercial products, modify weights, and deploy the models in environments where cloud terms and telemetry are not welcome: on-prem servers, edge devices, or fully offline systems. That makes Gemma 4 usable for firms with strict data residency requirements, for defense and critical infrastructure operators, and for companies that simply do not want their inference traffic routed through a single vendor’s API.
But “permissive” does not mean “frictionless.” The Decoder notes that Gemma 4 is built on the same underlying technology as Google’s proprietary Gemini 3, and the larger models advertise strong benchmark performance for their size—31B placing near the top of open-model leaderboards. The practical consequence is that the hard work shifts from licensing to operations: audits, safety testing, prompt-injection hardening, model monitoring, incident response, and documentation. In Europe, where AI compliance obligations are expanding, the cost of proving what a model does—and what it might do under adversarial use—can quickly exceed the cost of running it.
That dynamic tends to favour the largest players even when they “open” their models. Big firms can publish weights under a permissive licence and still keep an advantage through the parts that do not fit in a Git repository: legal teams that interpret shifting rules, red-teams that generate evidence for regulators and customers, and distribution channels that put a default model in front of millions of developers. Smaller companies may get freedom to run the model anywhere, but also inherit the liability and paperwork of deploying it.
Gemma 4’s hardware spread underscores the point. The smallest variants are pitched for mobile and IoT use, while the 26B MoE model activates only a fraction of its parameters per token to improve latency, and the 31B model is positioned as a base for fine-tuning. The more places a model can run, the more places an organisation must secure—and the more compliance becomes a budgeting line item rather than a policy slogan.
Google’s most “open” Gemma release arrives with a licence that gives developers broad rights. The bill for using those rights is increasingly paid in governance checklists, not GPU hours.