Anthropic data shows AI skill compounds with use
Claude veterans iterate more and succeed more often, productivity gains track process discipline and model budgets
Images
 Image description
the-decoder.com
Image description
the-decoder.com
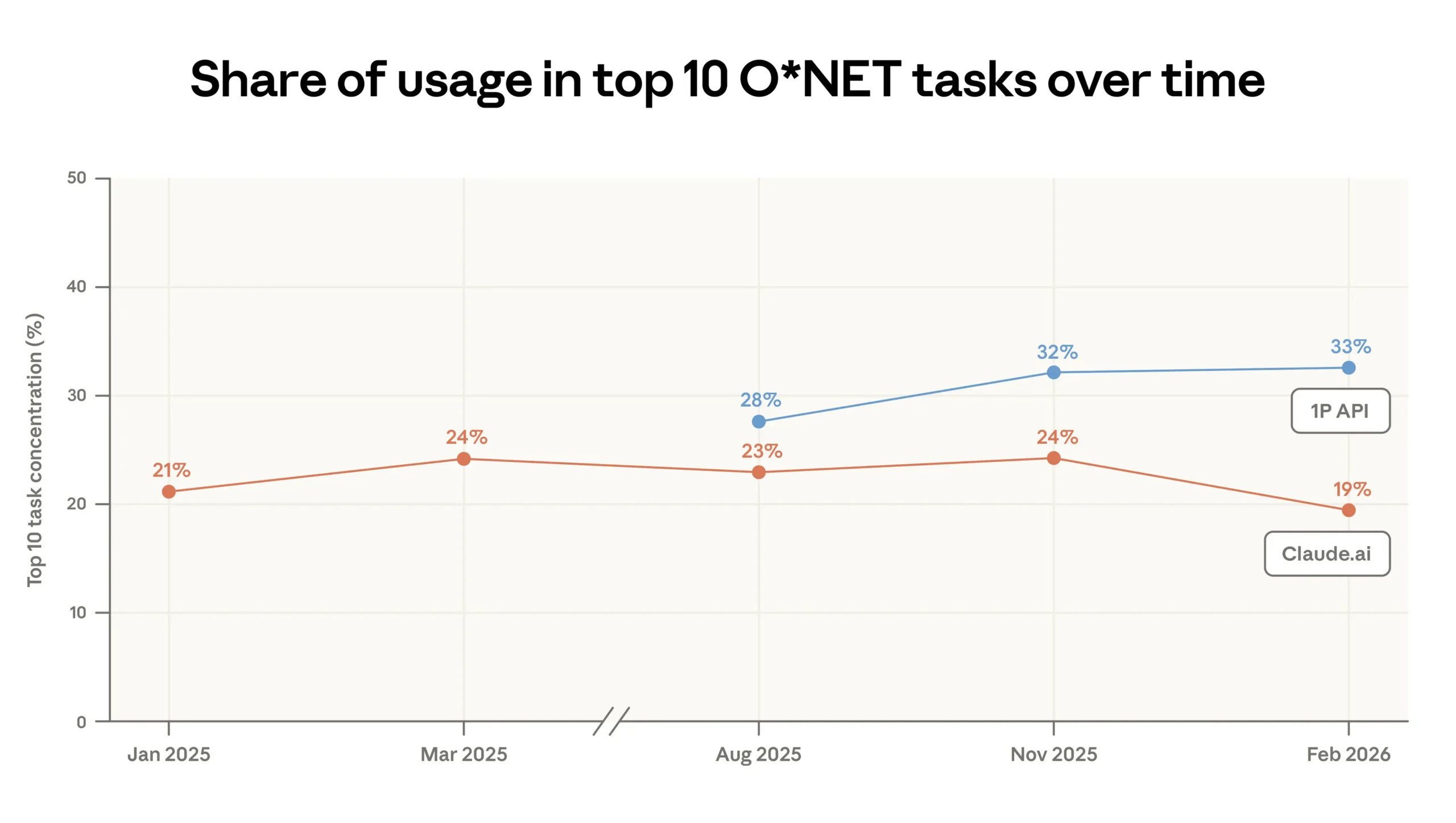 Usage on Claude.ai is becoming more widespread: the share of the ten most common tasks fell from 24 to 19 percent, while it rose to 33 percent in the API. | Image: Anthropic
Anthropic
Usage on Claude.ai is becoming more widespread: the share of the ten most common tasks fell from 24 to 19 percent, while it rose to 33 percent in the API. | Image: Anthropic
Anthropic
 Usage on Claude.ai is spreading out: the share of the ten most common tasks dropped from 24 to 19 percent, while API concentration rose to 33 percent. | Image: Anthropic
Anthropic
Usage on Claude.ai is spreading out: the share of the ten most common tasks dropped from 24 to 19 percent, while API concentration rose to 33 percent. | Image: Anthropic
Anthropic
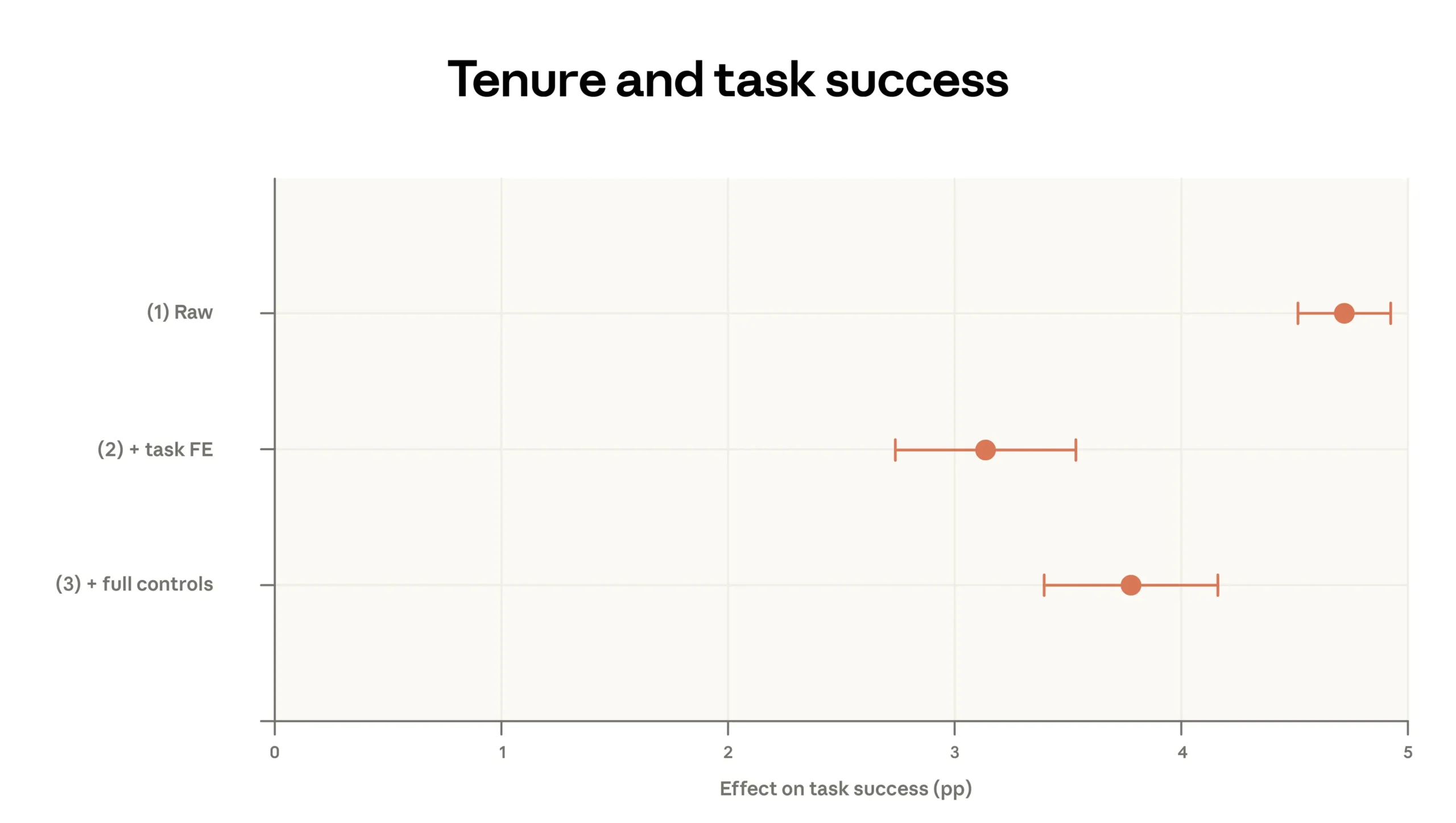 Anthropic measures success by having Claude evaluate anonymized transcripts to determine whether a conversation achieved its goal. The experience effect comes out to about four percentage points. | Image: Anthropic
Anthropic
Anthropic measures success by having Claude evaluate anonymized transcripts to determine whether a conversation achieved its goal. The experience effect comes out to about four percentage points. | Image: Anthropic
Anthropic
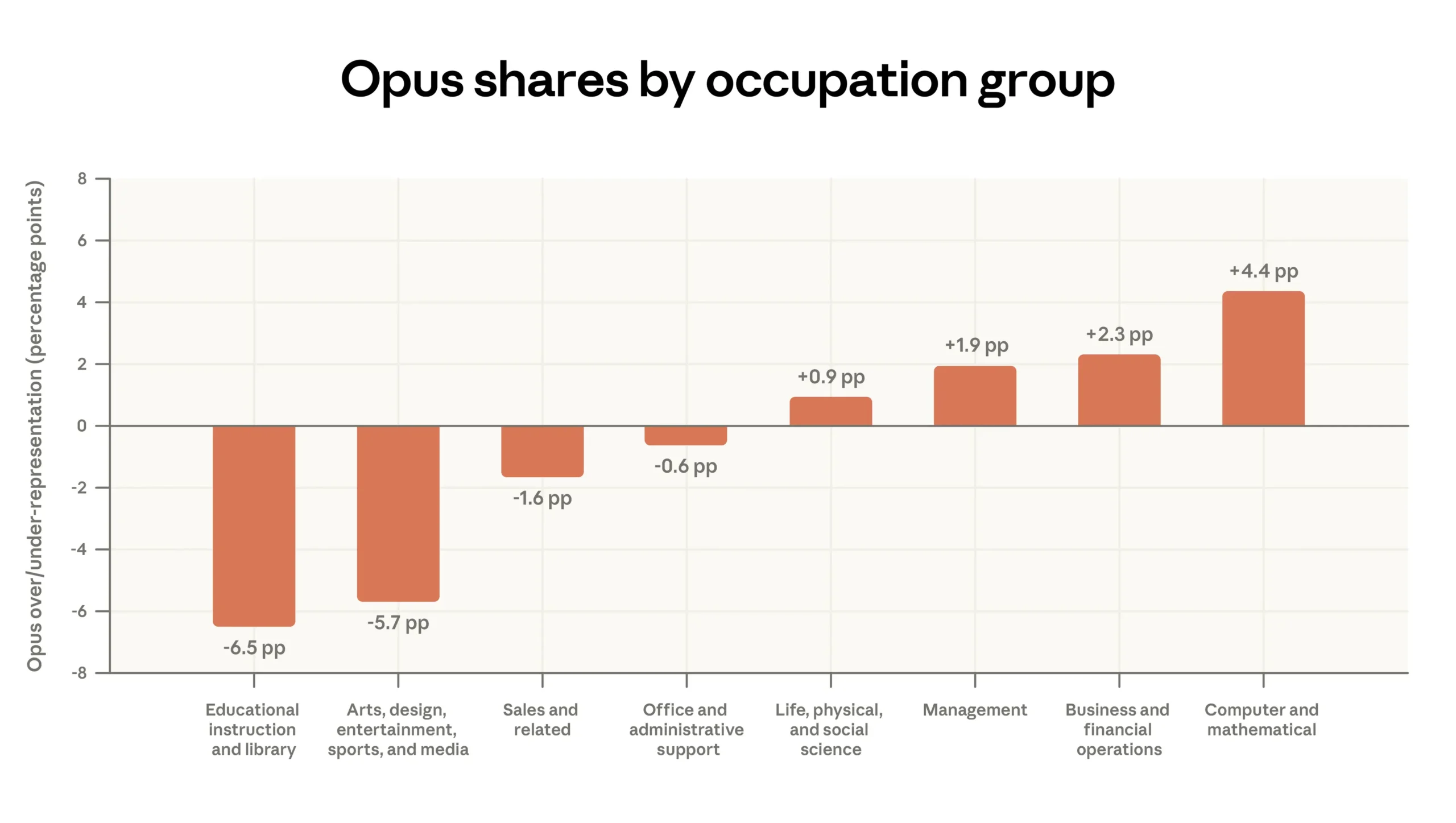 Users pick Opus specifically for demanding work. For computer and math tasks, Opus usage runs 4.4 percentage points above average; for educational tasks, it sits 6.5 points below. | Image: Anthropic
Anthropic
Users pick Opus specifically for demanding work. For computer and math tasks, Opus usage runs 4.4 percentage points above average; for educational tasks, it sits 6.5 points below. | Image: Anthropic
Anthropic
Anthropic says one million Claude conversations from February 2026 show a simple pattern: people get better at using the model the longer they use it. In its latest Economic Index report, the company finds experienced users are about four percentage points more likely to reach their goal than newcomers even when controlling for task type, model choice and country, according to The Decoder’s summary of the data.
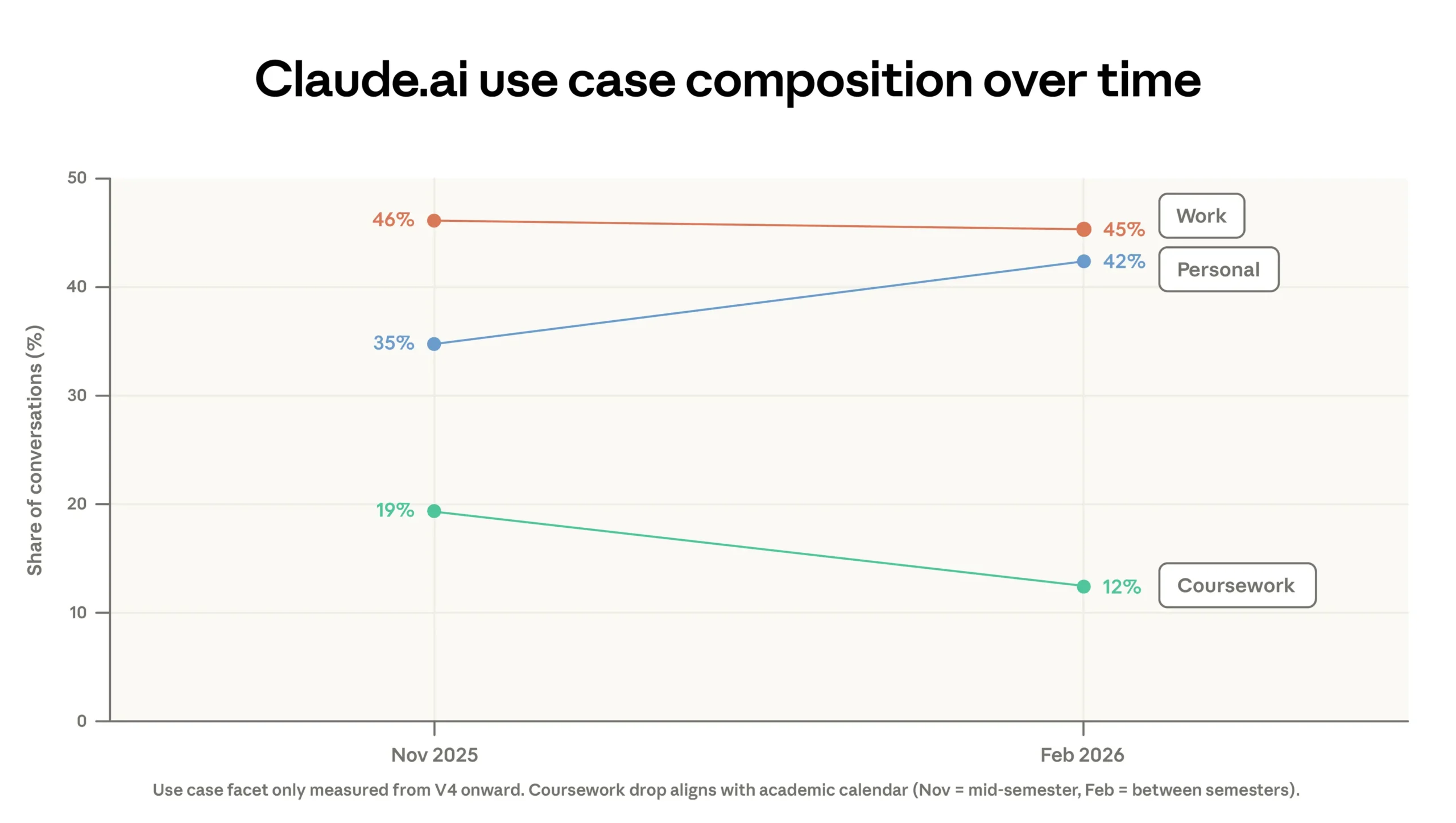
The distribution of what people do with Claude is also shifting. Coding remains the largest single category at 35% of usage, but more of that work is moving into Anthropic’s API products, including Claude Code, while the consumer-facing Claude.ai site is filling up with simpler personal requests. The share of “personal” prompts rose from 35% to 42% since the previous report, and the average “economic value” of tasks on Claude.ai—proxied by the hourly wages of the occupations associated with those tasks—fell slightly, from about $49 to $48 an hour.
That adoption curve matters because the report describes two different ways AI shows up inside organisations. New users tend to treat the model like a vending machine—one prompt, one output—while experienced users iterate, revise and collaborate. Anthropic reports that veterans are less likely to hand over a single instruction and more likely to refine their request through back-and-forth, and that they use the tool more often for professional work. At the high end of the experience scale, the tasks become recognisably “inside the workflow”: Git operations, manuscript revision and AI research, rather than poems and trivia.
The gap is not just taste; it is leverage. A four-point success-rate edge compounds when a tool is used dozens of times per week, and when better outputs mean faster decisions, fewer errors and more confidence to automate adjacent steps. It also rewards people who already have clean processes and domain knowledge—because the model’s output still needs to be specified, checked and integrated. In practice, that shifts value away from “AI for everyone” slogans and toward the people who can translate a messy business problem into a sequence of verifiable steps.
Anthropic’s model-choice data points in the same direction. Paying Claude.ai users pick the more capable Opus model disproportionately for complex work (55% of coding tasks versus 45% of educational tasks), while API users react even more strongly to task complexity. That is partly technical sophistication, but also budget authority: the people who can justify higher per-token costs tend to sit closer to revenue, risk or engineering.
Anthropic frames the results as a warning about widening inequality. The report’s own numbers suggest something more concrete: the advantage accrues to experienced users who iterate, and to organisations that can pay for better models and embed them into existing toolchains.
In February, the ten most common tasks on Claude.ai made up 19% of traffic, down from 24% three months earlier. The long tail is growing—but the compounding benefits appear to concentrate where the prompts come with checklists, codebases and someone paid to care about the output.