Microsoft deletes Azure tutorial linking pirated Harry Potter dataset
Kaggle listing mislabeled public domain and pulled after backlash, AI provenance remains mostly vibes until lawyers arrive
Images
 arstechnica.com
arstechnica.com
 arstechnica.com
arstechnica.com
 Photo of Ashley Belanger
arstechnica.com
Photo of Ashley Belanger
arstechnica.com
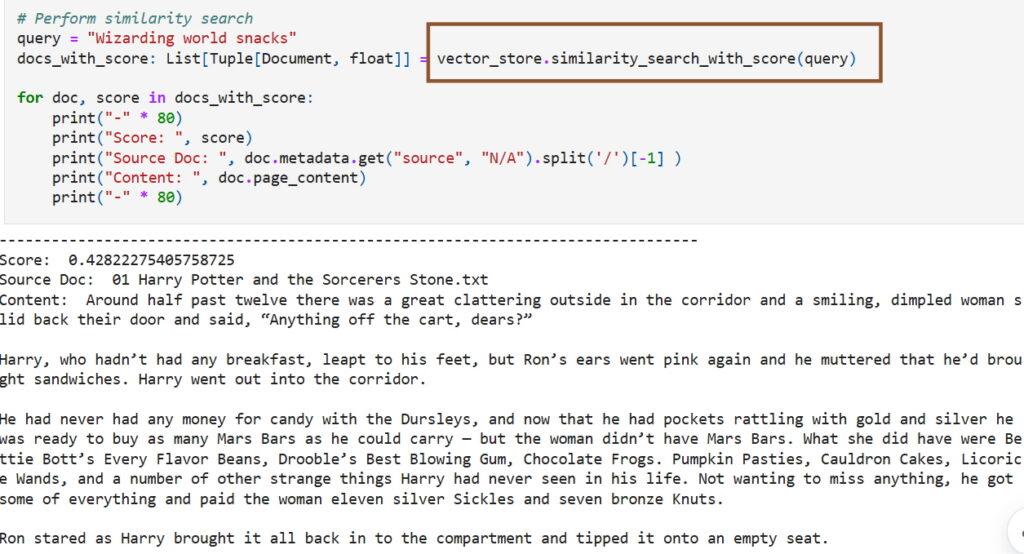
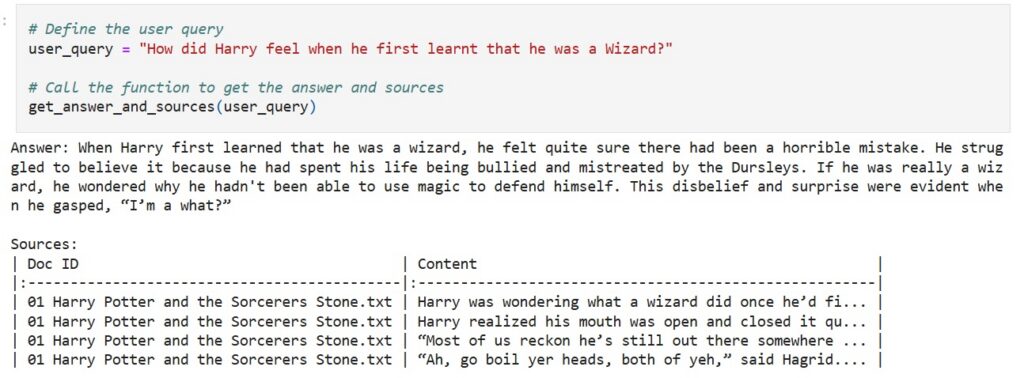
Microsoft has quietly deleted a developer blog post that walked readers through training a large language model on the full text of J.K. Rowling’s Harry Potter series—sourced from a Kaggle dataset incorrectly labeled “public domain.” Ars Technica reports the post, written in November 2024 by Microsoft senior product manager Pooja Kamath, was framed as a friendly demo of Azure SQL Database plus LangChain: upload the books to Azure Blob Storage, train an LLM, then build a question-answering bot or generate “AI-driven Harry Potter fan fiction.”
The embarrassment is not that a product manager missed the fine print of copyright terms. It’s that the post treated provenance as an afterthought—exactly the posture the AI industry has tried to normalize: scrape first, litigate later, and let “someone else” be responsible for licensing. The Kaggle dataset (downloaded roughly 10,000 times over years, per Ars) was removed only after the incident drew attention; the uploader told Ars it was marked public domain “by mistake.” Microsoft declined to comment.
The episode exposes how “dataset provenance” works in practice once you leave the press releases and enter the actual toolchains. LLM development at scale is a pipeline problem: ingestion, cleaning, deduplication, filtering, and training. Licensing metadata rarely survives those steps, and even when it does, it is often unverifiable. Kaggle’s platform terms allow takedowns and repeat-offender penalties, but they do not magically certify rights status. A dataset can sit in the open, mislabeled, until a rights holder notices—or until a large corporation links to it.
The industry’s preferred solution has been to treat provenance as a compliance layer bolted on afterward: “don’t train on copyrighted material” in policy documents, while engineering teams build systems that accept whatever text files fit into a blob store. In Kamath’s tutorial, the key innovation was not the books but the promise that adding generative AI features takes “just a few lines of code.” That is the real product: frictionless ingestion. Licensing friction is, inconveniently, also friction.
This is why serious provenance efforts—cryptographic content fingerprints, license registries, audit trails for training corpora—keep colliding with economic reality. If hyperscalers and model builders had to prove rights for every token, the cheapest datasets would no longer be “the internet,” and the scaling laws would start to look less like destiny and more like a procurement problem.
Microsoft’s deletion is the correct public-relations move. It does not change the underlying incentive: when compute is expensive and competition is brutal, the fastest route to a better model is still “more data,” and the easiest data is the kind you don’t have to negotiate for.