Google releases Gemini 3.1 Pro
Benchmarks show ARC-AGI-2 jump and modest gains elsewhere, Reasoning claims still unverifiable outside Google labs
Images
 Gemini 3.1 Pro benchmarks
Credit:
Google
Gemini 3.1 Pro benchmarks
Credit:
Google
 Photo of Ryan Whitwam
arstechnica.com
Photo of Ryan Whitwam
arstechnica.com
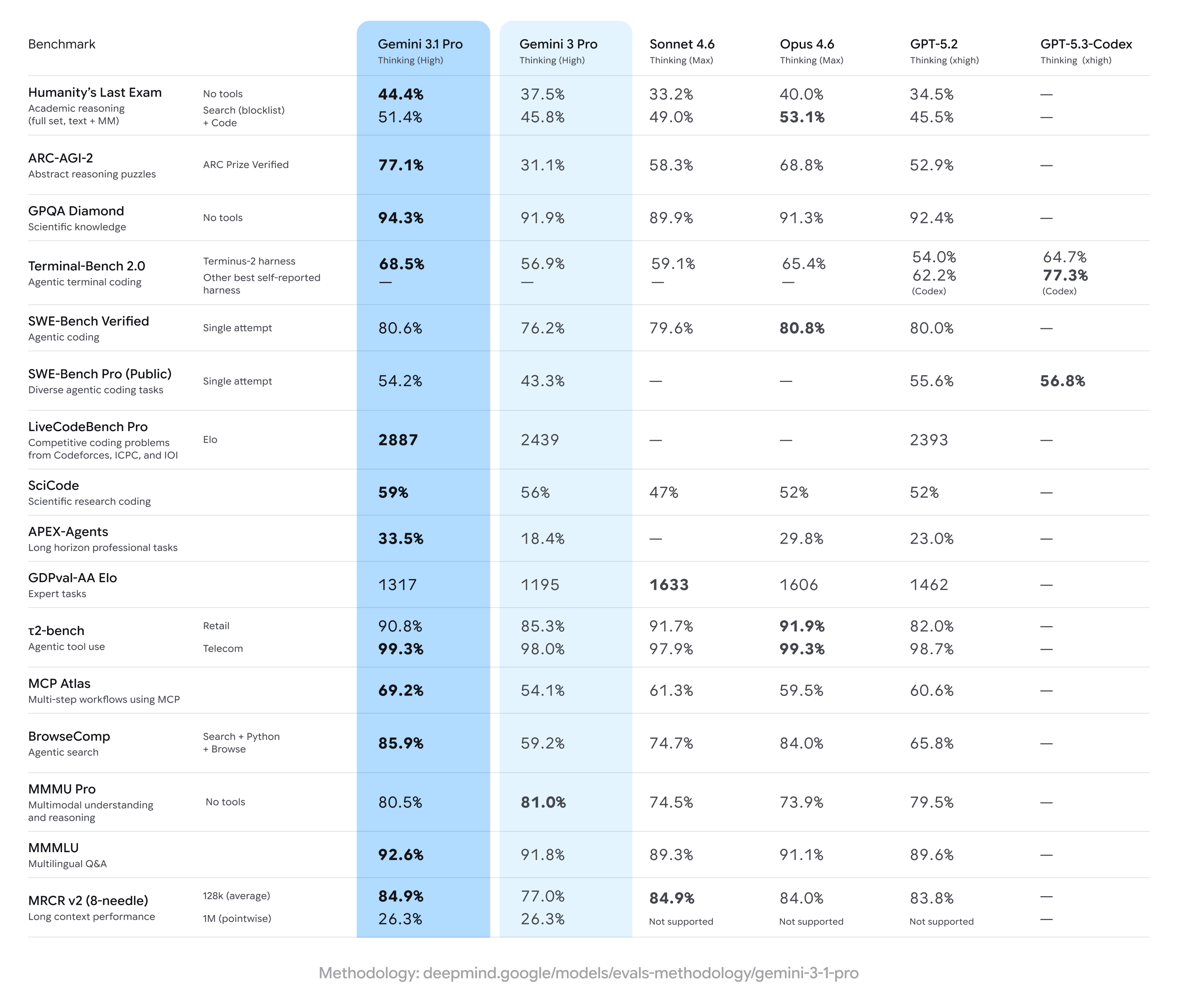
Google has announced Gemini 3.1 Pro, the latest incremental bump in its flagship model line, promising “better reasoning” and “complex problem-solving.” Ars Technica notes the familiar pattern: a wall of benchmark charts, a handful of curated demos, and the implicit demand that everyone treat a version number as an epistemic event.
On the headline numbers, Google claims a sharp jump on ARC-AGI-2 (77.1% versus 31.1% for Gemini 3 Pro), a benchmark designed around novel logic problems that are harder to brute-force via memorization. The Decoder similarly highlights ARC-AGI-2 as the marquee improvement and reports strong scores across other tests, including GPQA Diamond (94.3%) and near-parity with Anthropic on SWE-Bench Verified (80.6% vs 80.8% for Claude Opus 4.6). Google also touts agentic workflow gains, with Ars Technica citing an almost doubled APEX-Agents score.
But the same coverage also points to the chronic problem with AI performance claims: the gap between leaderboard wins and operational reliability. Ars Technica reminds readers that LM Arena-style rankings are “run on vibes,” rewarding outputs that look convincing rather than outputs that are correct. The Decoder adds that Gemini 3.1 Pro doesn’t top every benchmark—Anthropic leads on Humanity’s Last Exam with tool support, and Gemini 3 Pro slightly beats 3.1 Pro on MMMU Pro.
What actually changed? Not the economics or the hard constraints developers care about most. Ars Technica reports pricing is unchanged at $2 per million input tokens and $12 per million output tokens, and the context window remains 1 million input tokens with 64k output. Google is selling “reasoning” improvements without offering the kind of structural transparency that would let outsiders audit how those gains were achieved—data curation, synthetic training, tool-use policy changes, or benchmark-specific tuning.
That opacity matters because benchmarks are fragile. If a model family is trained, filtered, or fine-tuned in ways that inadvertently leak benchmark structure, the result is not “general reasoning,” it’s overfitting with better marketing. Even absent leakage, benchmark optimization can shift failure modes: a model that scores higher on puzzle-like tasks may become more confident, more verbose, and more wrong in domains where uncertainty should be surfaced.
Google is rolling Gemini 3.1 Pro out broadly—via the Gemini API, AI Studio, Vertex AI, the Gemini app, and NotebookLM, according to both Ars Technica and The Decoder. That distribution is the real story: a few percentage points on an eval sheet are less important than the fact that a single vendor’s model behavior is being wired into enterprise workflows, coding tools, and “agentic” automation.
The accountability question is simple: can customers reproduce Google’s claimed improvements on their own workloads, with their own test harnesses, and with logging that survives contact with compliance? Until then, “better reasoning” is just a press release with a token price.